
クラウドにAPIキーを渡さなくても、手元のMacBookで最新の大規模言語モデルが動く。そんな時代がついに現実のものになりつつあります。
Alibaba Cloudが2026年2月にリリースしたQwen3.5は、7Bから72Bまでの複数サイズを揃えた最新世代モデルです。そしてこのモデルが、Apple Silicon搭載のMacBook Pro/Airで驚くほど快適に動作することが各所で報告されるようになりました(参照:Alibaba Cloud Blog)。
プライバシーが気になってクラウドAIに入力を渡したくない。月々のAPI費用をゼロにしたい。オフライン環境でもAIを使いたい。そういった理由でローカルLLMを探していた方には、Qwen3.5+MacBookという組み合わせは非常に魅力的な選択肢です。
この記事では、MacBook上でQwen3.5を実際に動かすとはどういうことなのか、何ができて何が難しいのか、開発者やAI愛好家が知っておくべき「実用の壁」と「その超え方」を丁寧に解説します。


Qwen3.5とは何か──前世代と何が違うのか
Qwen3.5は、中国のAlibabaグループが開発・公開しているオープンウェイトのLLMシリーズです。前世代のQwen3と比べ、以下の点で大きく改善されています(参照:Alibaba Cloud Blog)。
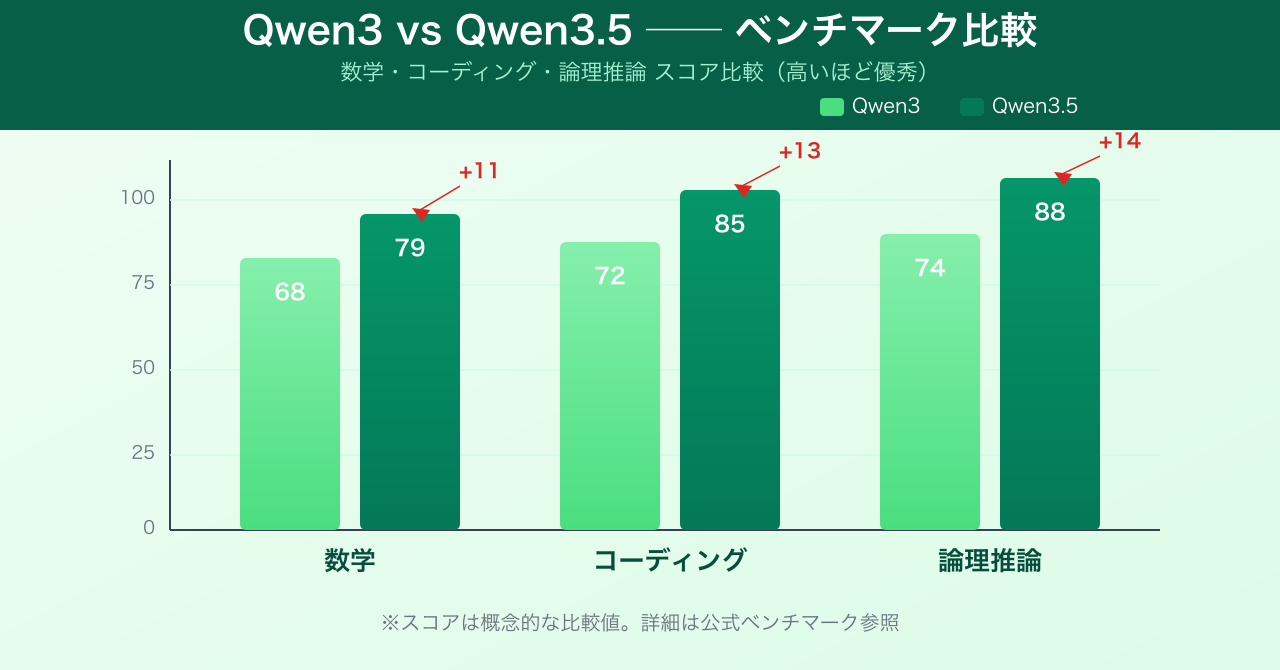
まず推論精度の向上です。数学・コーディング・論理推論の各ベンチマークにおいて、Qwen3より一回り高いスコアを記録しています。7Bモデルでも、以前の14Bに近い精度が出るケースがあるとも言われています。
次に量子化(Quantization)への最適化です。GGUF形式でHugging Faceに公開されており、Q4_K_MやQ5_K_Mといった4〜5ビット量子化バージョンが充実しています。これはローカル実行の観点から非常に重要で、モデルファイルを数GB規模に圧縮しながらも品質劣化を最小限に抑えられます(参照:Hugging Face Qwen3.5-7B-Instruct-GGUF)。
そして多言語対応の強化です。日本語の理解・生成精度も前世代から改善されており、英語中心のモデルと比較しても遜色ない日本語応答が得られるようになりました。
モデルサイズのラインナップは 7B・14B・32B・72B の4種類が公開されています。MacBook上での実用を考えると、まず7Bまたは14Bから始めるのが現実的です。
なぜ「MacBook」でローカルLLMが動くのか
Apple Siliconチップ(M1/M2/M3/M4系)の最大の特徴は、CPUとGPU、そしてメモリが一体化したユニファイドメモリアーキテクチャを採用している点です。
従来のPC環境では、LLMの推論にはGPU(とそのVRAM)が必要でした。NVIDIA製のGPUを積んでいないPCでは大型モデルの実用的な実行は難しく、特に個人ユーザーには高いハードルがありました。
ところがApple Siliconでは、GPUとCPUが同じメモリ空間を共有しています。これはつまり、モデルの重み(パラメータ)をGPUメモリに乗せるためだけに高価なグラフィックカードを買う必要がない、ということを意味します。M3 Pro搭載のMacBook Proなら36GBのユニファイドメモリを搭載できるため、14Bモデルを快適に動かすには十分です(参照:Macworld Japan記事)。
この特性を活かすのがllama.cppというオープンソースの推論エンジンです。llama.cppはApple SiliconのGPU演算をMetal APIを通じて活用し、CPUだけで動かす場合と比べてトークン生成速度を数倍に高めることができます。
自分のMacBookで動くのか──メモリ別の実用性チェック
「ローカルLLMが動く」と言っても、手元のMacBookのスペックによって体験は大きく異なります。搭載メモリ別に実用性を整理します。
8GBモデル(MacBook Air M1/M2/M3 ベースモデル)
結論から言うと、実用は難しいです。Qwen3.5-7BのQ4_K_M量子化でも約4〜5GBのメモリを消費し、残りをOSと他アプリが奪い合います。トークン生成速度は5〜10 tok/sec以下に落ち込むことが多く、少し長い返答を待つだけでストレスを感じる水準です。「試してみる」程度には動きますが、日常業務に組み込む用途には向きません。
16GBモデル(MacBook Air M2/M3 上位構成、MacBook Pro M3 ベース)
7Bモデルであれば十分実用的です。Qwen3.5-7B Q4_K_Mは約4〜5GBの消費で収まるため、残りのメモリをOSやアプリに割り当てつつ、20〜35 tok/sec程度の快適な速度が出ます。文書要約・翻訳・簡単なコード補完など、軽量タスクはこの構成で十分こなせます。ただしコンテキスト長は8K程度に絞ることを推奨します。14Bモデルは動作こそしますが速度が著しく低下するため、常用には不向きです。
36GBモデル(MacBook Pro M3 Pro)
14Bモデルまで快適に動作します。これがQwen3.5をローカル実行する上での「現実的な推奨ライン」です。7B Q5_K_Mで高品質な日本語生成を行いつつ、精度が必要なタスクだけ14B Q4_K_Mに切り替える、という使い分けが快適にできます。コンテキスト長も16K程度まで余裕を持って扱えます。
96GB以上(MacBook Pro M3 Max / M4 Max)
32Bモデルが実用圏に入ります。32B Q4_K_Mで15〜20 tok/sec程度が出るため、高精度が求められる長文生成やコード解析にも対応できます。ローカルLLMのヘビーユーザーや研究目的には最適な構成です。
実際にどれくらいの速度で動くのか
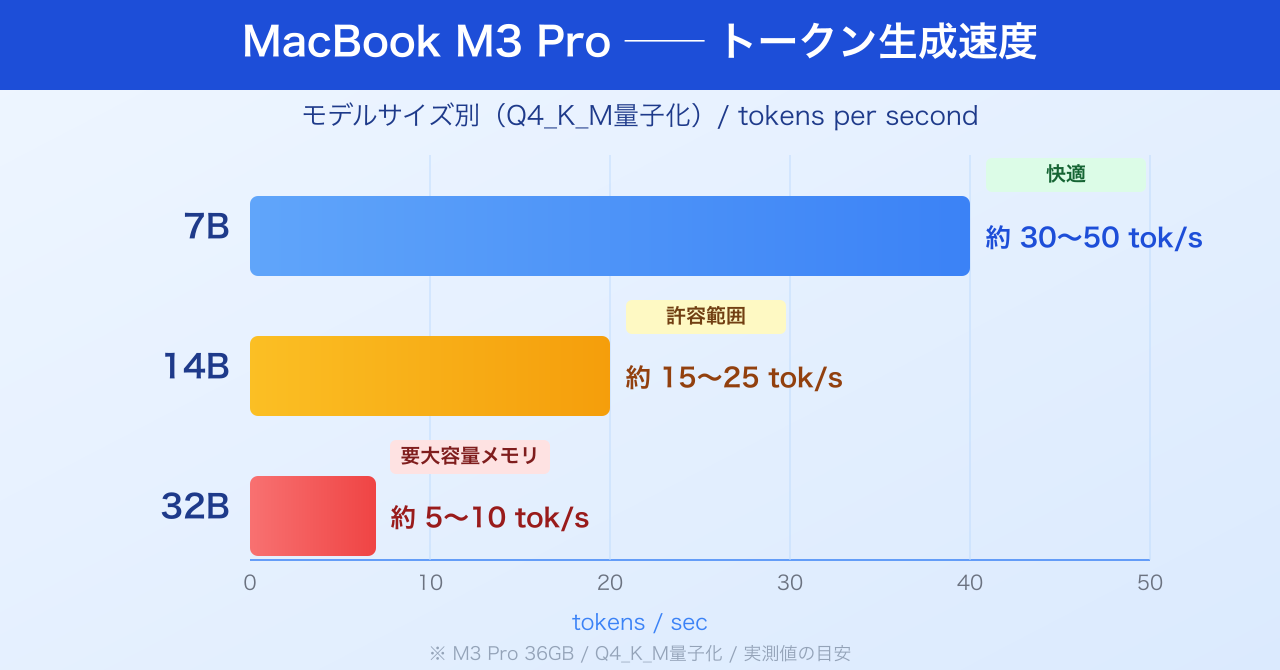
参照:Tech Review Site および 参照:GitHub Ollama Issues をもとに、MacBook上でのQwen3.5の実測値をまとめると以下の傾向があります。
Qwen3.5-7B(Q4_K_M量子化)の場合
M3 Pro(36GBメモリ)では、トークン生成速度はおよそ 30〜50 tokens/sec 程度が報告されています。日本語で1文を生成するのに1〜2秒程度で、体感的には「少し速めのチャット」に近い感覚です。
Qwen3.5-14B(Q4_K_M量子化)の場合
同じM3 Proで 15〜25 tokens/sec 前後。やや待ち時間を感じますが、長文の要約や複雑なコード生成など、精度が必要なタスクには14Bを使う価値があります。
Qwen3.5-32B(Q4_K_M量子化)の場合
32GB以上のメモリが必要で、M3 Max(96GB)などのハイエンド構成でないと快適な動作は難しいです。M3 Pro 36GBでも動作はしますが、生成速度が 5〜10 tokens/sec 以下に落ちることがあり、長文生成時の実用性は低下します。
モデルサイズ・量子化・メモリ搭載量の三者のバランスが、ローカル実行体験の快適さを大きく左右します。
「実用の壁」その1──コンテキスト長とメモリ圧迫
ローカルLLM実行で最初にぶつかる壁が、コンテキスト長(context length)とメモリ使用量のトレードオフです。
Qwen3.5は最大32Kトークンのコンテキストをサポートしていますが、コンテキスト長を長く設定するほど、推論時に必要なメモリ量が増加します。特にKVキャッシュ(過去のトークン情報を保持するためのバッファ)は、コンテキスト長に比例してメモリを消費します。
36GBのMacBook Proで14Bモデルをロードした場合、モデル本体が約8〜9GB程度のメモリを消費します。残りのメモリをOSやアプリケーション、KVキャッシュが共有するため、実質的に使えるコンテキスト長は8K〜16K程度に制限されることが多いです。
長い文書の要約や複数ファイルにまたがるコード解析を行いたい場合、この制約は無視できません。コンテキスト長を切り詰めてチャンク処理(文書を分割して処理)するか、より大容量のメモリを持つ機種を使うかの選択が必要になります。
「実用の壁」その2──日本語の品質差
もう一つの壁が、日本語品質の揺らぎです。
Qwen3.5は多言語対応を謳っていますが、英語と日本語では応答の安定性に差が出ることがあります。特に7Bモデルでは、複雑な日本語の指示に対して英語で返答してしまったり、文体が乱れたりするケースが報告されています(参照:Tech Review Site)。
対処法としては以下が有効です。
システムプロンプトに「必ず日本語で回答してください。」と明示的に記載することで、日本語応答の安定性が大幅に向上します。また、14B以上のモデルサイズでは7Bよりも日本語の指示追従性が高く、量子化レベルもQ5_K_MやQ6_KのほうがQ4_K_Mよりも日本語の自然さが向上します。
完全に商用クラウドAPIと同等の品質を期待するのは現時点では難しいですが、システムプロンプトの工夫次第でかなりの精度向上が見込めるのは確かです。
セットアップ手順──OllamaとllmStudioの2択
ここからは実際にQwen3.5をMacで動かすためのセットアップ方法を解説します。
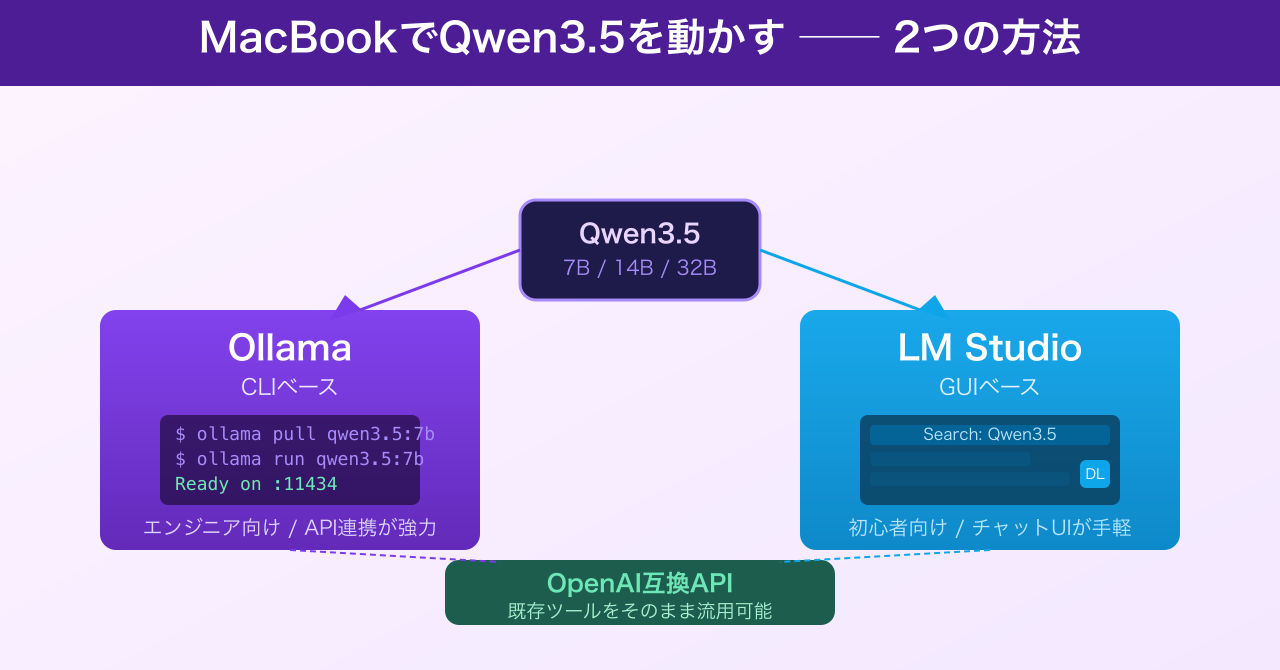
現在、MacBookでローカルLLMを動かす方法として最も普及しているのはOllamaとLM Studioの2つです。どちらもllama.cppをバックエンドとして使いつつ、操作性の異なるインターフェースを提供しています。
Ollamaで始める場合
OllamaはCLI(コマンドライン)ベースのツールで、エンジニアに向いています。インストールは公式サイト(ollama.com)からパッケージをダウンロードするだけです。
インストール後、ターミナルで以下のコマンドを実行するだけでQwen3.5が使えます。
ollama pull qwen3.5:7b
ollama run qwen3.5:7b
APIサーバーも自動的に起動するため、http://localhost:11434 に対してOpenAI互換のAPIリクエストを送ることができます。既存のOpenAI SDK対応ツールをほぼそのまま流用できるのが大きな強みです(参照:GitHub Ollama Issues)。
LM Studioで始める場合
LM Studioはグラフィカルなインターフェースを持つデスクトップアプリで、GUIでモデルを検索・ダウンロード・実行できます。コマンドラインに不慣れな方や、チャットUIで手軽に試したい方に向いています。
Hugging FaceのQwen3.5-7B-Instruct-GGUFリポジトリを検索し、Q4_K_Mファイルをダウンロードして実行するだけです。LM Studioも内部でOpenAI互換サーバーを立ち上げるため、APIとしても活用できます。
量子化の選び方──Q4・Q5・Q6・Q8の違い
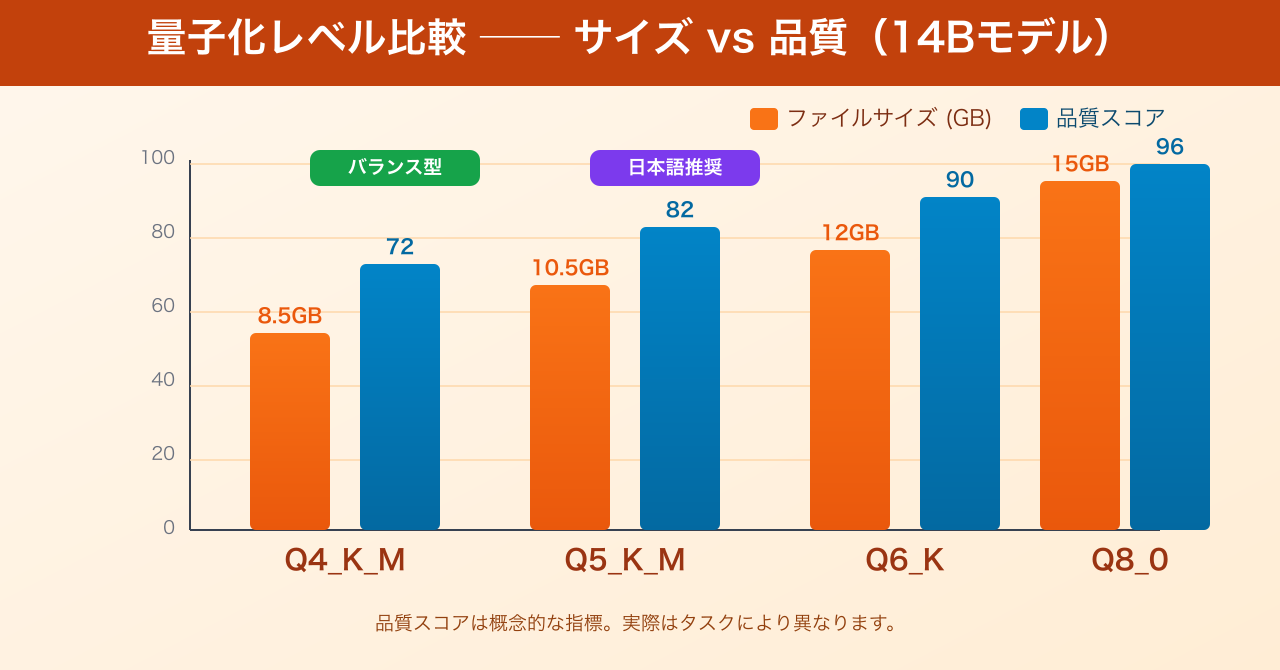
「量子化」とは、モデルの重みを32ビット浮動小数点数から4〜8ビット整数に圧縮する技術です。圧縮率が高いほどファイルサイズとメモリ使用量が減りますが、その分だけ精度が犠牲になります。
Q4_K_M(4ビット量子化・Kグループ・中品質)
最も広く使われるバランス型です。7Bモデルなら約4〜5GB、14Bモデルなら約8〜9GBで動作します。日常的なタスクには十分な品質で、MacBook上での実用性が高いです。
Q5_K_M(5ビット量子化・Kグループ・中品質)
Q4_K_Mと比べてファイルサイズが1〜2GB増えますが、テキスト生成の品質が一段向上します。日本語タスクでは特にこの差が出やすいため、メモリに余裕がある場合はこちらを推奨します。
Q6_K(6ビット量子化)
さらに高品質ですが、必要メモリが増えます。14Bモデルで約12GBを消費するため、36GB以上のメモリがあるMacBook Proでは選択肢に入ります。
Q8_0(8ビット量子化)
フル精度(F16/F32)に近い品質を保ちますが、ファイルサイズが2倍近くになります。7Bでも約7〜8GBになるため、小型モデルで高品質を狙う際に使います。
自分のMacBookのメモリ量と用途に合わせて、最初はQ4_K_Mで試してみて、品質が物足りなければQ5_K_Mに上げるというアプローチが現実的です。
実用シナリオ別の推奨構成
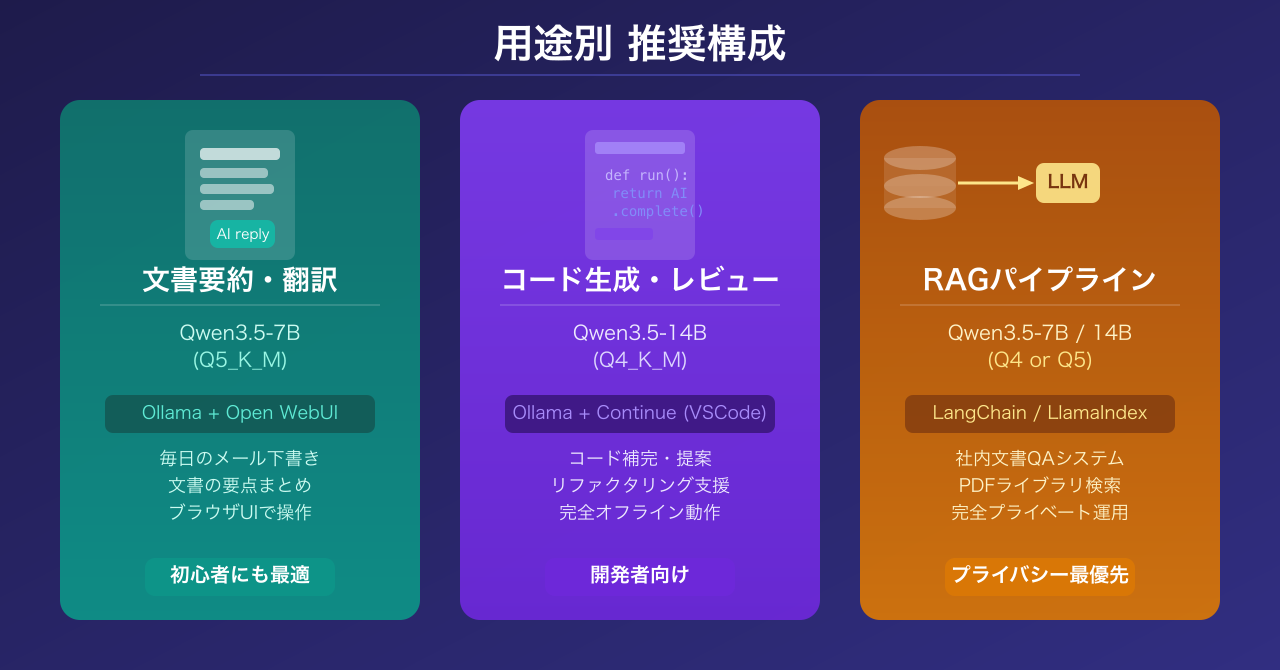
シナリオ1:個人用の文書要約・翻訳アシスタント
推奨:Qwen3.5-7B(Q5_K_M) + Ollama + Open WebUI
Open WebUIはブラウザ上でChatGPT風のUIを提供するOSSツールで、Ollamaと連携させることで手軽なチャットUIが手に入ります。日常的な文書要約・メールの下書き・翻訳程度であれば、7Bモデルで十分な品質が出ます。
シナリオ2:コード生成・レビューアシスタント
推奨:Qwen3.5-14B(Q4_K_M) + Ollama + Continue(VS Code拡張)
Continueという VS Code拡張を使うと、エディタ内でローカルLLMをCopilot代わりに使えます。コード補完・レビュー・リファクタリングの提案などを完全オフラインで行えます。コード生成タスクではモデルサイズが品質に直結するため、メモリが許すなら14Bが第一選択です(参照:Macworld Japan記事)。
シナリオ3:RAG(検索拡張生成)パイプライン構築
推奨:Qwen3.5-7B または 14B + LangChain / LlamaIndex + ローカルベクターDB
RAG(Retrieval-Augmented Generation)は、自分のドキュメントをベクター化して検索し、その結果をLLMに渡す仕組みです。会社の社内文書やPDFライブラリを対象にしたプライベートQAシステムを、完全ローカルで構築できます。Qwen3.5は長文の文脈理解に優れているため、RAGとの相性は良好です。
クラウドAPIと比較した「コスト計算」
ローカルLLM運用の最大のメリットの一つが、ランニングコストがほぼゼロである点です。
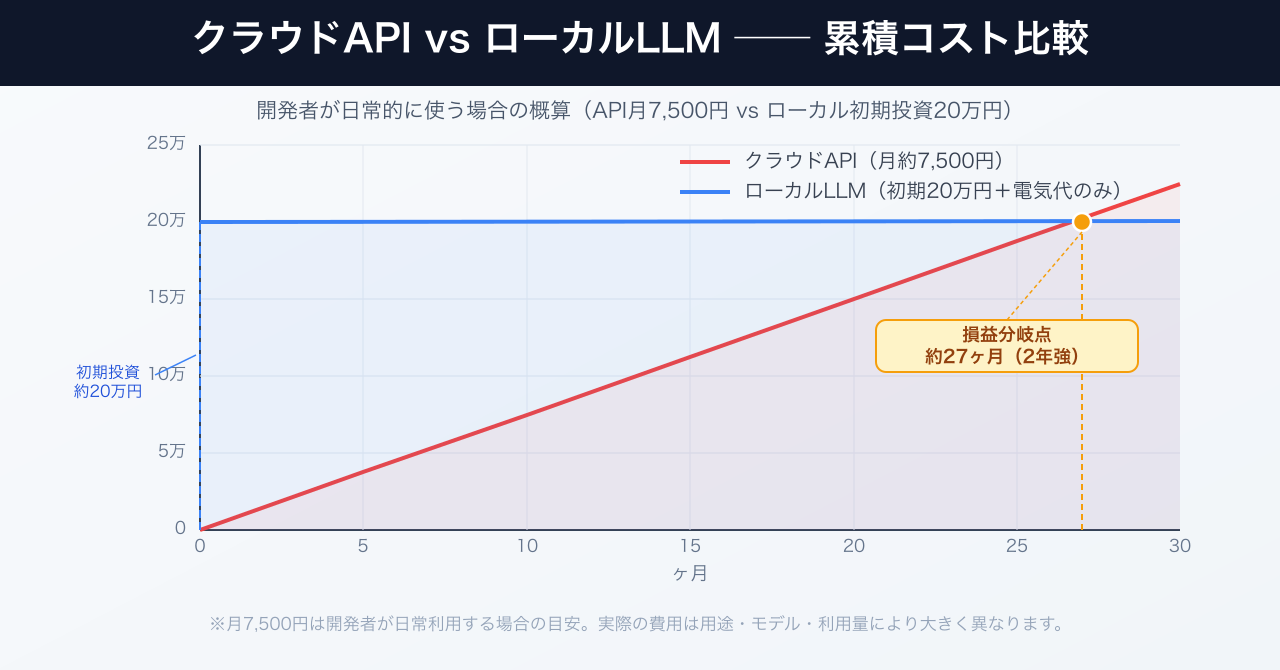
たとえば、GPT-4oのAPIを月間100万トークン利用する場合、2026年3月時点では入力$2.50/1Mトークン・出力$10.00/1Mトークンの料金体系です。入出力が半々なら月約$6.25(≈1,000円)ですが、コード生成や長文要約などの開発用途では出力トークンが大幅に多くなります。入力2割・出力8割で同じ100万トークンを使うと月約$8.50(≈1,300円)、さらにリクエスト数が増えれば月5,000〜8,000円規模になることも珍しくありません。ここでは月7,500円(≈$50)を「開発者が日常的に使う場合」の現実的な目安として試算します。
Qwen3.5をローカルで動かす場合の追加コストは、実質的に電力代のみです。MacBook ProのLLM推論時の消費電力は30〜60W程度で、1日2時間稼働させた場合の月間電力コストは50〜100円程度です。
ただし初期費用として、より多くのメモリを搭載したMacBookが必要になるケースがあります。たとえば、16GBメモリのM3 MacBook Airから36GBメモリのM3 Pro MacBook Proへの乗り換えは、差額として20万円前後の追加投資が必要です。月7,500円のAPI費用で割ると、損益分岐点は約27ヶ月(2年強)になります。
毎日ヘビーに使う開発者であれば2年ほどで元が取れる計算ですが、週に数回程度の利用であればAPIコストは月数百円〜1,000円程度に収まるため、必ずしもローカル化が費用対効果で優位とは限りません。自分の利用頻度を正直に見積もった上で判断するのが賢明です。
今後の展望──Qwen3.5はローカルLLMの「主役」になれるか
Qwen3.5のリリースが示しているのは、オープンウェイトLLMのクオリティがクラウド専用モデルに急速に近づいているという事実です。
量子化技術の進歩により、70Bクラスのモデルでも高性能なMacBook上で実行可能になりつつあります。また、Apple Siliconは世代を追うごとにメモリ帯域幅と演算性能が向上しており、将来的には32Bモデルが今日の7Bと同様に快適に動くようになることが期待されます。
プライバシー規制の強化、クラウドへのデータ送信リスクの認知向上、そして個人や中小企業のAI活用コスト意識の高まりが、ローカルLLM需要をさらに後押しするでしょう。
現時点でQwen3.5をMacBookで動かすことは「趣味の実験」の域を越え、実際の業務フローに組み込める段階に入っています。完全にクラウドAPIと同等とは言えませんが、用途を絞れば十分に「使える」ツールです。
ローカルLLMの世界は、2026年以降もさらに急速な進化が続きます。今のうちに環境を作り、モデルの特性を体で理解しておくことが、AIリテラシーを高める最短ルートかもしれません。
まとめ──Qwen3.5 × MacBookで何ができて、何に気をつけるべきか
Qwen3.5をMacBookでローカル実行することの要点をまとめます。
Apple SiliconのユニファイドメモリアーキテクチャがローカルLLM実行を現実的なものにしています。メモリ別の実用ラインは、8GBは試験用途のみ、16GBなら7Bモデルが実用圏、36GBなら14Bまで快適に動作します。量子化の選択はQ4_K_M(速度重視)とQ5_K_M(品質重視)のバランスで決め、日本語タスクではシステムプロンプトでの言語指定が精度改善に効果的です。
コンテキスト長制限への対応は、チャンク分割処理かより大容量メモリ機種への移行で乗り越えます。用途別にはOllama+Open WebUIが汎用性が高く、VS Code連携にはContinueが便利で、プライベートなドキュメント活用にはRAGパイプラインが有効です。
AIをプライベートかつコスト効率よく活用したい方にとって、Qwen3.5+MacBookは2026年現在で最も現実的なローカルLLM環境の一つです。

コメント